
PowerShell7のInvokeWebRequest()にはParsedHtmlが残念ですが無いので、別の方法を考えてみます。
class=foo1
class=foo2
id=bar
 ぱくたその「がちゃ」で引いた画像
ぱくたその「がちゃ」で引いた画像HTMLのソース
<div class="foo">class=foo1</div>
<div class="foo">class=foo2</div>
<div id="bar">id=bar</div>
<div class="imglist"><img src="https://maywork.net/wp/wp-content/uploads/2022/05/shinbunGFVL9617_TP_V4-300x200.jpg" alt="経済新聞に目を通す情報通" width="300" height="200" class="size-medium wp-image-8039" /> ぱくたその「がちゃ」で引いた画像</div>
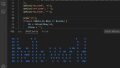
PowerHTMLモジュールのインストール
Install-Module -Name PowerHTMLPowerShellスクリプト
$url = "https://maywork.net/computer/powershell-html-dom/"
$html = Invoke-WebRequest -Uri $url | ConvertFrom-HTML
# idで絞込
$html.SelectNodes("//div[@id=""bar""]").innerText
# classで絞込
$html.SelectNodes("//div[@class=""foo""]") | % { $_.innerText }
# classで絞込後tagで絞込
$html.SelectNodes("//div[@class=""imglist""]/img") | % {
$_.Attributes["src"].Value
$_.Attributes["alt"].Value
}PowerShellスクリプトの実行結果
id=bar
class=foo1
class=foo2
https://maywork.net/wp/wp-content/uploads/2022/05/shinbunGFVL9617_TP_V4-300x200.jpg
経済新聞に目を通す情報通PowerShell Galleryでモジュールを探してみたところPowerHTMLというモジュールが良さそうなので試してみました。
![]()
![]()
PowerShell5.1でInvokeWebRequest().ParsedHtmlで取得した結果と同じ値を取り出すことが出来ました。

![]()
PowerHTMLはHTML Agility PackというC#のライブラリをPowerShellからアクセスしやすくしたラッパーとのことですが、XPathでHTML要素を指定しています。
XPathは初めて扱いましたが、直感的でわかりやすい記述方法だと思いました。

PowerHTML 0.1.7
Provides a wrapper for HTML Agility Pack for use where the IE HTML DOM from Invoke-WebRequest is not available such as P...
www.powershellgallery.com
PowerShell5.1でInvokeWebRequest().ParsedHtmlで取得した結果と同じ値を取り出すことが出来ました。
PowerShellでHTMLから要素の情報をDOMで取得する。
PowerShellのInvoke-WebRequestコマンドレットでHTMLページを取得したオブジェクトにParsedHTMLというプロパティがあります。こちらのプロパティをDOMでアクセスすることで各要素を取り出すことが出来ます。cl...
maywork.net
2022.05.17
PowerHTMLはHTML Agility PackというC#のライブラリをPowerShellからアクセスしやすくしたラッパーとのことですが、XPathでHTML要素を指定しています。
XPathは初めて扱いましたが、直感的でわかりやすい記述方法だと思いました。
追記:20250215
久しぶりにとあるサイトの検索結果をPowerShellでスクレイピングしてみました。
$html.SelectNodes("//div[@id=""web""]/ol/li/a")HTML全体(Bodyかも)からdiv要素でidがwebを指定。(idはページ内でユニークのはずなので1つの要素に絞られるはず。)
さらにol⇒li⇒aと指定していますが、この条件に当てはまるaが複数戻ると思われます。
htmlの例
<div id='web'>
<h2>ウェブ</h2> <!-- ここは無視 -->
<ol>
<li><a href='https://mayworks.net'>迷惑堂本舗</a><div>ページの要約</div></li>
<li><a href='https://sample.net'>サンプル</a><div>ページの要約</div></li>
...
</ol>
</div>
複数の要素に対して処理を行う場合、PowerShellではForEachコマンドレットをパイプラインでつなげて各要素の処理を行えます。
$html.SelectNodes("//div[@id=""web""]/ol/li/a") | ForEach-Object {
Write-Host ("タイトル:" + $_.innerText);
Write-Host ("url:" + $_.Attributes["href"].Value);
Write-Host ("要約:" + $_.NextSibling.innerText)
}a要素の文字列を取得する場合innerTextで取得出来ます。(迷惑堂本舗)
a要素のリンクアドレスは、Attributes["href"].Value(https://mayworks.net)
a要素の次のdiv要素の文字列はNextSibling.innerTextで取得することが出来ました。(ページの要約)
SelectNodesで取得されるオブジェクトは引数のXPathに当てはまる全ての要素が取得できるようで、途中idやclassなどの絞り込み条件を用いると、柔軟な条件検索が可能となっています。
こちらの方法は昔ながらの静的なWebページや、動的にページを生成するサイトの場合でもサーバーサイドでページを生成している場合有効です。しかしながら最近のWebページではJavaScript等のテクノロジを使ってクライアントサイドでコンテンツを生成するケースが増えており、そのようなタイプの場合残念ながらこちらの方法は使えません。
そのような場合はWebブラウザのレンダリングの結果を取得できるSelenumなどの出番に成ります。

![]()
PythonのSeleniumとBeautifulSoupでWebページからテキストを抽出する。
SeleniumでWebブラウザ(Google Chrome)でWebページを表示し、ブラウザ内で表示されたページの内容(HTML)をBeautifulSoupで解析します。Seleniumのインストールchromedirver.exeはイ...
maywork.net
2025.01.21
コメント